Personally I have used partitions and bucketing for hive few times.
But since Hive supports these two features I should note them here.
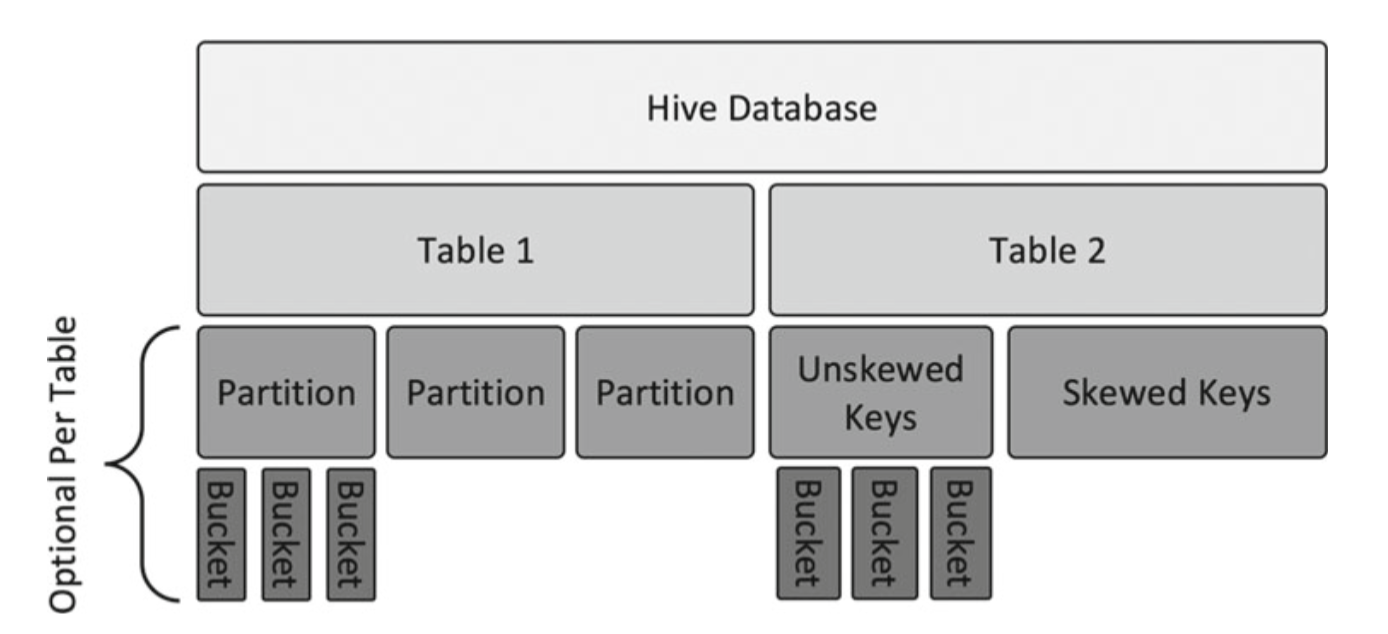
Here is the partitions sample below.
hive> create table transactions_int (
> transdate date,
> transid int,
> custid int,
> fname string,
> lname string,
> item string,
> qty int,
> price float) partitioned by (store string);
OK
hive> INSERT INTO transactions_int PARTITION (store="new york") values ("2016-01-25",101,109,"MATTHEW","SMITH","SHOES",1,112.9);
hive> show partitions transactions_int;
OK
store=new york
Time taken: 0.276 seconds, Fetched: 1 row(s)
hive> select * from transactions_int;
OK
2016-01-25 101 109 MATTHEW SMITH SHOES 1 112.9 new york
Time taken: 0.424 seconds, Fetched: 1 row(s)
When you check files from hdfs command you will see the storage space is separated by partition keys.
$ hdfs dfs -ls /user/hive/warehouse/transactions_int
Found 1 items
drwxr-xr-x - pyh supergroup 0 2022-05-12 10:07 /user/hive/warehouse/transactions_int/store=new york
Partitoning considerations:
Return to home | Generated on 09/29/22